Finding a string within another string is something you do quite often when programming. In this post, I will discuss some well-known string-matching algorithms, present their theoretical performance, and measure them in practice. I will show you that there is a big difference between the theoretical performance of these algorithms, and how well they perform in practice.
| Algorithm | Theoretical runtime complexity |
| Brute-force | O(n*m) |
| Knuth-Morris-Pratt | O(n+m) |
| Rabin-Karp | O(n+m) |
Problem definition
We define the problem of string matching as: given an input string and a pattern, find the first occurrence of the given pattern in the input string.
We define n: the length of the input string and m: the length of the pattern to search for.
Naïve implementation
We’re starting out with the most straightforward way of string matching. This brute-force approach is actually often used in practice, as it does not require dynamic memory allocation and does not require any pre-processing.
The runtime of the brute-force approach is O(n*m), but don’t let this distract you from the relatively high performance this algorithm achieves in practice.
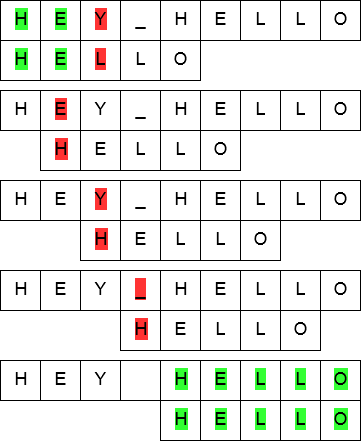
The above figure illustrates the working of the brute-force algorithm. For each position in the input string, it simply iterates through the pattern, matching character by character. If the entire pattern is processed and matched, it means the pattern was found in the input string.
This algorithm is used by many of the well-known C++ compilers (MSVC++, Clang and GCC all use it). Later in this post, I will show why exactly this algorithm is the top choice for these major compilers.
Knuth-Morris-Pratt algorithm
The Knuth-Morris-Pratt algorithm for string searching works nearly the same as the brute-force implementation. The important difference is that when there is a mismatch between the input string and the pattern string, the algorithm knows where the next match in the input string could begin, meaning it does not re-check any characters that have been matched already.
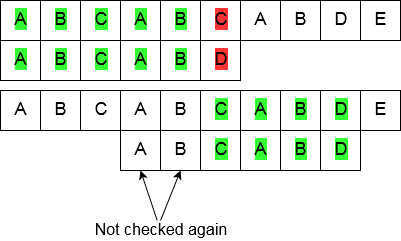
To achieve this partial-match tracking, a table is prepared. This table indicates the position of the character in the pattern string to start matching from after a mismatch during searching.
Knuth-Morris-Pratt table building
As described, building a partial match table is important as it is needed to maintain the O(n+m) runtime of the algorithm.
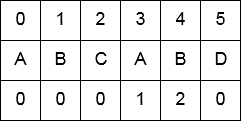
The figure below shows what such a table looks like for the pattern string “ABCABD”, the bottom row in the table shows the amount of characters matched when, during iteration over the pattern, a mismatch is detected. It can be seen that, for this input, a mismatch at position 5 (the letter “D”), the string “AB” is still matched, meaning the matching will start off at position 2 (the letter “C”) for the iteration over the remainder of the input string.
Rabin-Karp algorithm
In the Rabin-Karp algorithm, the string matching is done by comparing hash values of the pattern string and the substrings in the input string. In case the hash values are equal, a check of the actual string is done. This check needs to be done as equal hash values do not mean the strings are equal as well (the other way around does hold: equal strings mean equal hash values).
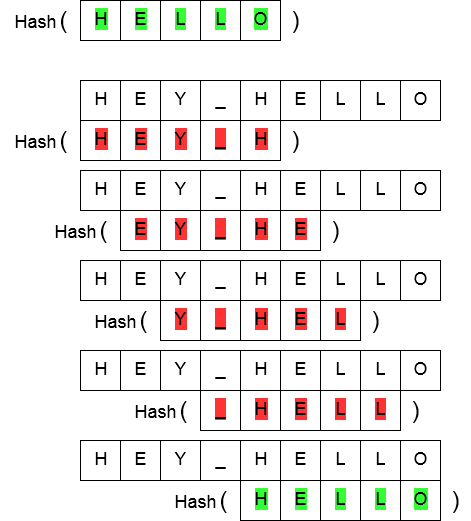
Efficient calculation of substring hash values is extremely important. If these hash values were calculated in a naïve way (e.g. calculating hash values by iterating over all possible substrings), a runtime of O(n*m + m) would be achieved, meaning this algorithm would have the same theoretical complexity as the naïve string search algorithm. A runtime of O(n+m) could be achieved however, by using what’s called a rolling hash.
Rolling hashes and the Rabin fingerprint
A rolling hash, as the name suggests, takes a part of the full string to search in, and calculates its hash based on the hash of the previous substring. It takes the hash of the earlier substring, and “forgets” the earliest character in that substring (as this character will no longer be part of the current substring). Then, it used this new character to update the hash. All this can be done in constant time: no iterating over substring characters has to be done, just an operation on the earliest character in the old hash and the new character.
The Rabin fingerprint is an example of a hashing method using rolling hashes.
Experiments and results
To measure the performance of these algorithms in practice, the discussed string-matching algorithms were implemented in C++. Measurements were done on these algorithms with different string lengths n and pattern lengths m, and are presented below.
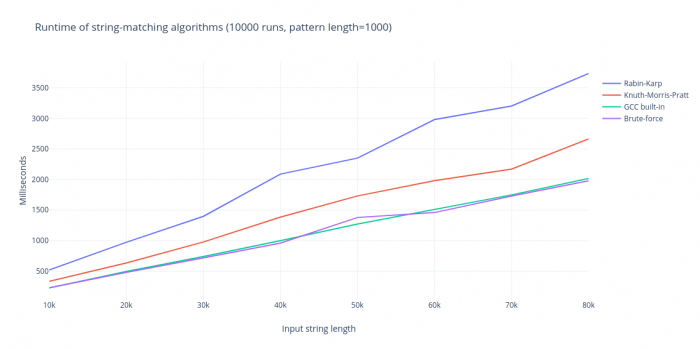
As seen in the above figure, the brute-force approach has the best performance of all discussed methods, even though it has the worst theoretical complexity. Reasons for this fast and seemingly linear performance include:
- No setup phase, the algorithm can immediately start searching for the pattern;
- Low probability of partial matches in practice, meaning the pattern string is not iterated through often, leading to a seemingly linear runtime;
- Possibility of low-level optimizations: comparing multiple characters at once, predictable memory access, etc.
Even with increased pattern lengths, the brute-force algorithm will not be affected in practice. The other two algorithms will see a slight increase in running time, as their setup phase is dependent on the pattern length. This can be seen in the figure below.
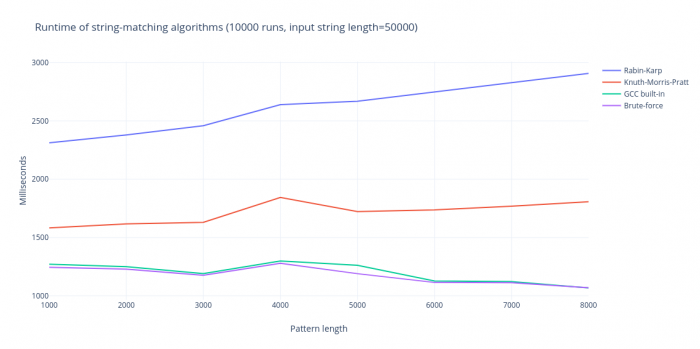
Conclusion
As discussed, there is a notable difference between the theoretical performance of some of the discussed string searching algorithms and their practical performance. In this case, using theoretically better but more complicated algorithms will not result in higher performance. A theoretically worse, but practically much simpler algorithm shows the best performance!
The source code for these algorithms and the results of the measurements are available at: https://github.com/daankolthof/string-matching-algorithms.