This article will discuss trees, binary search trees and algorithms related to these data structures.
A binary search tree is a tree-based data structure that keeps its nodes in sorted order. The exact workings of this ordering and sorting will be described later in this post. Because of this sorting, a binary search tree can have a more efficient runtime for some common data structure operations (compared to a list of elements):
| Operation | Average complexity | Worst case complexity |
| Searching | O(log n) | O(n) |
| Insertion | O(log n) | O(n) |
| Deletion | O(log n) | O(n) |
| Space complexity | O(n) | O(n) |
Traversing a tree
Before we dive into the binary search trees, it’s useful to know the two general ways of traversing any tree: depth-first search and breadth-first search.
Depth-first search
Depth-first traversal is a technique in which branches of a tree will be fully explored before taking steps back and traversing other branches/leaves. An example of a post-order depth-first traversal is shown in the following image:
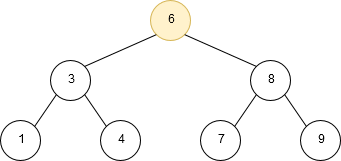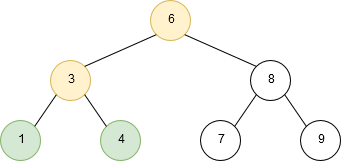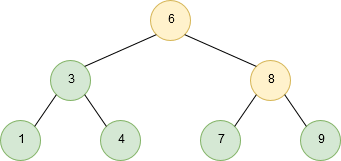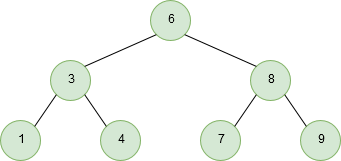
The three most common traversal orders for depth-first search are:
- Pre-order traversal: visit current node first, then children.
- In-order traversal: visit left child first, then current node, then right child.
- Post-order traversal: visit children first, then current node.
Breadth-first search
The other way of traversing a tree is breadth-first search, where the different layers of a tree will be traversed one-by-one. This means that the root layer (containing one node) will always be visited first, then all nodes in the next layer, etc.
In practice, this is usually done by putting nodes to visit in a queue. Using a queue guarantees certain nodes (those less deep in the tree) will be visited/processed first.
Finding an element in a binary search tree
The binary search tree is a special case of a tree. In a binary search tree, every node has the following property: the left child-node and its sub-children have values smaller than the current node’s value; the child-node and its sub-children have values greater than the node’s value. The earlier shown tree is an example of a binary search tree.
Using this property, we can traverse this binary search tree much more efficiently. Simply start with the root and determine whether to check left or right, depending on the value to find. For example: in the above tree, we find the value 7 by starting at the root node (6) and going right (as 7 is greater than 6) and then left (as 7 is smaller than 8).
Binary search tree insertion and deletion
For insertion and deletion, we have to make sure the tree is still a valid binary search tree after doing the insert of delete operation.
Insertion is relatively simple. We traverse the elements in a binary search tree, going left or right depending on the value to insert and the current node’s value. When we find a node that has no child in the position we need to visit, we simply insert the new value at that position.
An example of insertion into a binary search tree is given below:
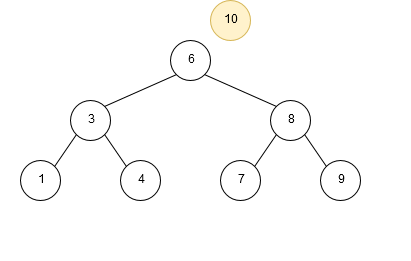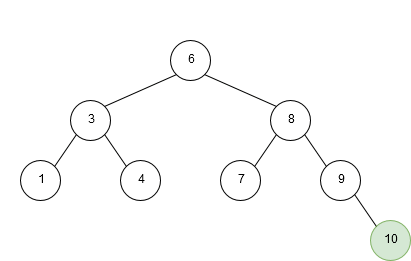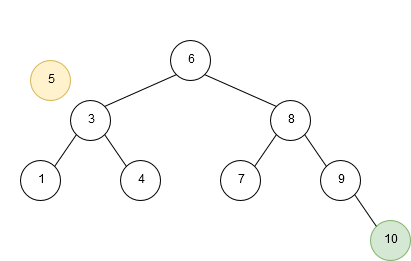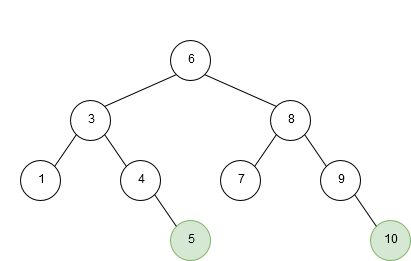
Deletion of a node in a binary search tree is a bit more complex. To keep the nodes in order after deletion, we have to account for three different scenarios:
- Removing a node with no children: Remove the node.
- Removing a node with one child: Remove the node. Have the parent node point to the child node (re-point the left or right child pointer in the parent node).
- Removing a node with two children: Set the value of this node to the smallest value that’s larger than the current node’s value (go right one step, then go left until you can’t go left anymore) or the largest value that’s smaller than the current node’s value (go left one step, then go right until you can’t go right anymore). Then, remove the node you took the value from (using scenario 1 or 2).
Verification
If we construct a binary search tree using the insertion and deletion steps as detailed above, no further verification is needed. If we get a tree that’s already constructed, checking whether this tree is a binary search tree is done by making sure that, for each node, the left subtree only contains values smaller than the current node’s value and the right subtree only contains values larger than the current node’s value.
This checking is usually done by recursively calling all nodes in the tree, and by keeping track of the minimum and maximum allowed values as parameters in these recursive calls. See the source code on GitHub: https://github.com/daankolthof/TreeAlgorithms
Algorithms using binary search trees
The node ordering and efficient lookup give way to a number of algorithms that use binary search trees:
- Sorting: Elements in a binary search tree can be retrieved in sorted order when doing in-order traversal.
- Lookup: Elements can be found on average in O(log n) time, which is an improvement compared to naïve lookup, in which elements in a list are checked one-by-one: O(n).
- Priority queues: The smallest (or largest) element can be retrieved and removed in O(log n) time. New elements can also be inserted in O(log n) time. The runtimes of these operations allow for an efficient implementation of a priority queue (a queue in which elements are prioritized based on the order of their values).
Other tree-based algorithms
Other interesting algorithms/data structures based on trees are:
- Red-black trees
- AVL trees
- Dependency trees
- Topological sort
Conclusion
Trees, including binary search trees, are data structures that are often more useful and more efficient in storage, lookup, sorting and/or determining the order of objects compared to non-tree-based data structures (lists, etc). Using these tree-based data structures can often be the way to go in tackling certain problems or to implement certain algorithms.
The source code for the algorithms discussed in this post is available at: https://github.com/daankolthof/TreeAlgorithms.