When writing large scale software, caching is a valuable technique that offers more rapid lookup of data. Caches, especially in-memory key-value stores, provide a quick and easy way to retrieve values given a certain key. In-memory caching can be much faster than traditional (relational) database queries, which often result in disk reads or writes on a database server.
In this post, I will be exploring the least recently used (LRU) cache, a mechanism often used in practice when you want to avoid time-consuming database queries and instead read from (much faster) memory. While an LRU cache does not have to be in-memory, in practice it often is and we will be exploring the theory and implementation behind such in-memory LRU caches.
LRU ordering
Least recently used ordering, as the name implies, orders elements within a data structure by the last time these elements were accessed (that is, the last time these elements were read or written). Next to LRU caching, a few other caching strategies exist. Some of the more well-known caching strategies include:
- Least recently used
- Most recently used
- First in first out
- Last in first out/first in last out
- Least frequently used
LRU Ordering and deletion of elements
Since computers (and thus in-memory caches) do not have an infinite amount of memory, a good ordering and deletion strategy is needed. Deletion strategy in this case refers to the way elements are deleted when they are no longer relevant and/or when caching memory has ran out.
The least recently used ordering is quite straightforward in this case. When memory runs out, elements that were accessed the longest time ago are deleted. This can be easily done as the LRU cache keeps track of the usage of elements. How many elements to delete when memory runs out is up to the implementation of the cache.
Design of an LRU cache
Now that we know how to order elements within an LRU cache, and we know we need to be able to read and insert elements in this cache, we can design an LRU cache as follows:
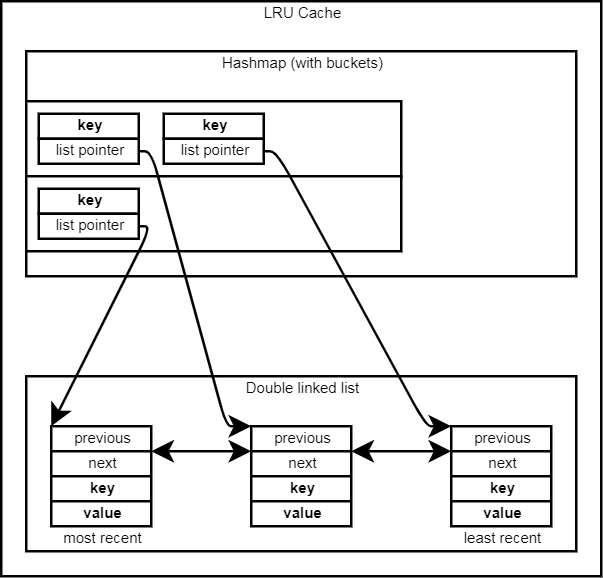
With this design, two important data structures are used: a hashmap and a double linked list. The hashmap allows for constant-time lookup of elements when they are read and/or changed. The double linked list allows for the cache to track the usage of elements. The very first element in the linked list is the least recently used element, the last element is the element used the longest time ago (and will be up for deletion first if needed).
Before we describe the actual operations, an overview of the runtimes of these operations is as follows:
| Operation | Runtime |
| Querying a value | O(1) |
| Inserting a new element | O(1) |
| Changing an existing elements’ value | O(1) |
In practice, there is one exception to these runtimes which must be mentioned: caches running out of memory when doing one of these operations. The average runtime remains the same, even if clean-up is needed now and then. This is because every element can only get deleted once and this deletion can happen constant time.
However, when deletions happen because of a cache running out of memory, the operation that leads to the memory running out will take longer than average, as the deletion will be done at that time as well.
Querying a value
To retrieve a value associated with a certain key from the LRU cache, the following steps are done:
- Check the hashmap to see if the key is available in the LRU cache. If the key is not available, return as there is no value to be found.
- Follow the pointer in the hashmap to the key-value node in the linked list.
- Take the key-value node out of the linked list by having its previous node and next node point to each other.
- Set this key-value node as the first node in the linked list, as it is now the most recently used element (since we just queried it).
- (Optional step, can make implementing step 3 and 4 easier) Update the node pointer in the hashmap if the actual key-value node is reconstructed.
- Return the value that was found in the key-value node.
Inserting a new element
Inserting a new element in the LRU cache is done using the following steps:
- Check the hashmap to make sure the key is not found in the LRU cache already.
- Construct a new key-value node in the linked list with the given new key and value.
- Insert the key and node pointer in the hashmap.
- In case memory runs out, clean up elements that were used the longest time ago.
Changing an existing elements’ value
Changing an existing element’s value is done using the exact same steps as querying the value, with just one extra step added, after all other steps are done:
- After setting the key-value pair as least recently used, change the value to the new given value.
The source code for the LRU algorithms discussed in this post is available at: https://github.com/daankolthof/LRU-memory-cache.